
Industrial Landscape, Ashton-under-Lyne, by Laurence Stephen Lowry
Discovering Consumers' Ideal New Product:
Conjoint Analysis With Excel
Have you ever faced the situation where you have to decide which product to buy among a multitude others? This is becoming increasingly commonplace for the American consumer:
 |
Do you pick a product formulated to freshen breath, control tartar, combat plaque, or attack gingivitis? Do you select another if you’re older than 50, have sensitive teeth, sensitive gums, or sensitive enamel? And that’s just the tip of the iceberg. We know, because those are just some of the 27 varieties of Crest we recently bought at a single supermarket. (For Colgate, we found a mere 25.) |
The above explosion has serious consequences for business professionals - especially for entrepreneurs. For example, in order to introduce a new product, powerful retailers often require companies to pay slotting allowances, which are fees paid solely to place the new product on the shelf. Furthermore, a proliferation of new products in the shelf make choices harder for consumers.
In the light of these challenges, savvy marketers must understand which new products are most likely to survive in a retailer’s shelf, and what market share to expect, before they are introduced. In other words, you must determine what consumers' ideal new product is, and how well it will do on the shelves, before introducing it!
Conjoint analysis is a useful tool to this end, and has helped firms of all sizes design new products and services - most famously the Courtyard by Marriott hotel chain. Specifically, using conjoint analysis, the entrepreneur can (1) determine how preferred each product attribute is, (2) in consequence, how preferred a potential new product will be, and (3) what is the likely market share that will result from introducing a new product.
What's the advantage over entrepreneurs that do not use Conjoint Analysis?
Market-oriented entrepreneurs will have advantages with their target market and with investors if they use Conjoint Analysis:
In the light of these challenges, savvy marketers must understand which new products are most likely to survive in a retailer’s shelf, and what market share to expect, before they are introduced. In other words, you must determine what consumers' ideal new product is, and how well it will do on the shelves, before introducing it!
Conjoint analysis is a useful tool to this end, and has helped firms of all sizes design new products and services - most famously the Courtyard by Marriott hotel chain. Specifically, using conjoint analysis, the entrepreneur can (1) determine how preferred each product attribute is, (2) in consequence, how preferred a potential new product will be, and (3) what is the likely market share that will result from introducing a new product.
What's the advantage over entrepreneurs that do not use Conjoint Analysis?
Market-oriented entrepreneurs will have advantages with their target market and with investors if they use Conjoint Analysis:
|
Type of entrepreneur |

Myopic
|

Market-oriented
|
|
Market advantage
|
A myopic entrepreneur will launch a new product with insufficient information about consumer preferences. This is likely to result in an unsuccessful product introduction.
|
A market-oriented entrepreneur will first determine the ideal product that consumers want, based on solid analysis of their preferences, and then introduce it, minimizing risk of failure.
|
|
Investor advantage
|
This entrepreneur will come to investor meetings without understanding how much will consumers like his or her product. This can generate suspicion and invite slotting allowance charges, which both diminish the entrepreneur's potential of securing investor funds.
|
This entrepreneur will back up his claims with real data on consumers' preference for an ideal new product. Also, the entrepreneur will be able to predict the market share resulting from the new product introduction. This is likely to give investors' more confidence and potentially lower slotting allowances.
|
What do entrepreneurs need to determine consumers' ideal product?
How can entrepreneurs determine consumers' ideal product?
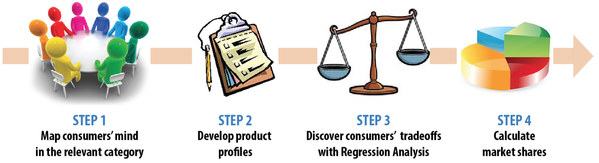
To determine consumers' ideal product, the entrepreneur needs to go through the four steps that constitute a conjoint study:
- A survey that records consumers' ratings for product profiles - that is, for different types of products, where different means has different attributes. These ratings can be on a scale of 1 to 7, 1 to 9, or 1 to 10. For example, one could determine 12 different product profiles, and ask consumers to rate each of those profiles from 1 to 10.
- Software packages, namely Microsoft Excel.
How can entrepreneurs determine consumers' ideal product?
To determine consumers' ideal product, the entrepreneur needs to go through the four steps that constitute a conjoint study:

|
|
To begin our discussion, it is useful to think of products as a "bundle of attributes". Everything you buy as a consumer, and market as an entrepreneur, can be understood in this way. You may never look at a box of Frosted Flakes in the same way again!

Figure 1: What's in a box of Frosted Flakes?
In Figure 1, we have defined Frosted Flakes as a product with:
Our assumption, when thinking about products as bundles of attributes, is that every product possesses one level of each attribute. Therefore, any product in the market could be summarized using a combination of these attributes - a profile. Now, if we believe that flavor, shape, and marshmallows are the main three attributes in the market for cereals, how many products could we potentially design? By multiplying the number of levels in each attribute, it can be seen that the number of potential product profiles is 3x2x2 = 12.
Why do we need Conjoint Analysis? Couldn't we simply ask people to tell us how much they prefer each attribute in a certain product category, and use those preferences to design new products? There are two potential problems with this approach:
The need for obtaining revealed preferences, and the difficulty of articulating them, calls for a statistical method that allows you to recover these revealed preferences in a simple way. When you are thinking about developing a new product, and you want the above, Conjoint Analysis is the way to go!
- Three main attributes that consumers think about when buying a product, service or idea.
- Each attribute, in turn, has levels, that is, the various different expressions of the attributes a product contains.
- In the case of Frosted Flakes, the attribute levels that compose them are sugary flavor, flake shape, and presence of marshmallows. This is known as the product profile of Frosted Flakes.
Our assumption, when thinking about products as bundles of attributes, is that every product possesses one level of each attribute. Therefore, any product in the market could be summarized using a combination of these attributes - a profile. Now, if we believe that flavor, shape, and marshmallows are the main three attributes in the market for cereals, how many products could we potentially design? By multiplying the number of levels in each attribute, it can be seen that the number of potential product profiles is 3x2x2 = 12.
Why do we need Conjoint Analysis? Couldn't we simply ask people to tell us how much they prefer each attribute in a certain product category, and use those preferences to design new products? There are two potential problems with this approach:
- First, what consumers state may not necessarily reflect what they truly prefer. This is a big issue when developing controversial or sensitive products, or products that the consumer wants to use to signal a certain status they may not want to admit. Thus, ideally, you should use a method that allows you to recover consumers' preferences from their actual, observed choices. These are called revealed preferences.
- Second, even if consumers were willing to truthfully reveal their preferences, sometimes these are hard to articulate. For example, you may be able to articulate how much you prefer one car, or one house, from another, and do so attribute by attribute, because these are high-involvement products. But how about toothpaste? Detergent? Toilet paper? In situations where the product you want to introduce is a low-involvement product, obtaining accurate preference estimates is an issue regardless of how truthful consumers are.
The need for obtaining revealed preferences, and the difficulty of articulating them, calls for a statistical method that allows you to recover these revealed preferences in a simple way. When you are thinking about developing a new product, and you want the above, Conjoint Analysis is the way to go!

|
Step 1:
|
The first step in the Conjoint Analysis study is to determine what attributes, exactly, do consumers consider when purchasing within the product category of interest. For example, when thinking about purchasing a new laptop computer, do consumers think about their speed? Display quality? Size? Weight? Hard drive size? These attributes are generally uncovered through a series of focus groups. Furthermore, the relevant levels within each attribute must be determined as well. For example, how many laptop computer sizes do consumers generally consider? Note that, unlike a perceptual map study, here we are not as interested in the mind map itself. The crux is to obtain consumers' preferences for product attributes.
Some attributes may not be objective, but rather subjective. For example, a 2008 study by Luo, Kannan and Ratchford show how consumers perceive a power drill along a series of objective attributes (such as shape, switch type, and weight) as well as two subjective attributes (perceived power and comfort). Their research shows that incorporating these subjective attributes into product profiles may allow us to obtain more information on what the ideal product for consumers is.
Some attributes may not be objective, but rather subjective. For example, a 2008 study by Luo, Kannan and Ratchford show how consumers perceive a power drill along a series of objective attributes (such as shape, switch type, and weight) as well as two subjective attributes (perceived power and comfort). Their research shows that incorporating these subjective attributes into product profiles may allow us to obtain more information on what the ideal product for consumers is.

|
|
After determining the relevant product attributes, and their corresponding levels, a set of product profiles must be developed, and then coded into an SPSS file, Excel spreadsheet, and so forth. You can see an example of product profiles in a conjoint survey here. The objective is to develop profiles that consumers will then rate according to their preference. The idea is that by knowing how much they like a particular product profile, you can infer how much they like each separate attribute level.
Recall that the number of levels for each attribute must be multiplied. Consequently, when the number of attributes and/or levels is very large, you may not be able to show all potential profiles to consumers. In that case, only a smaller set of profiles may be shown. Designing these is outside of the scope of the course, but interested students may wish to read on fractional factorial experimental designs.
These profiles are developed with a technique called "dummy coding". With dummy coding, we create a file with a number of columns equal to the number of levels in our study. Each row represents a product profile, and each column represents a particular attribute level. In each cell, the number "1" denotes that a particular profile has that attribute level, and the number "0" denotes the absence of that level.
Recall that the number of levels for each attribute must be multiplied. Consequently, when the number of attributes and/or levels is very large, you may not be able to show all potential profiles to consumers. In that case, only a smaller set of profiles may be shown. Designing these is outside of the scope of the course, but interested students may wish to read on fractional factorial experimental designs.
These profiles are developed with a technique called "dummy coding". With dummy coding, we create a file with a number of columns equal to the number of levels in our study. Each row represents a product profile, and each column represents a particular attribute level. In each cell, the number "1" denotes that a particular profile has that attribute level, and the number "0" denotes the absence of that level.
| Profile | Sugar | Chocolate | Unflavored | Flakes | Nuggets | Marshms. | No Marshms. |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 0 | 0 | 1 | 0 | 0 | 1 |
| 2 | 1 | 0 | 0 | 0 | 1 | 0 | 1 |
| 3 | 0 | 1 | 0 | 1 | 0 | 1 | 0 |
Table 1: Three cereal profiles: Can you describe them?
For example, in Table 1, Profile 1 represents Frosted Flakes (i.e. a sugary cereal, with flake shape, and no marshmallows); Profile 2 represents a version of Frosted Flakes with nuggets instead of flakes; Profile 3 is a new cereal that has chocolate flakes and marshmallows. IMPORTANT: Remember that products can have NO MORE THAN ONE LEVEL per attribute! In other words, a product can't both have and not have marshmallows at the same time!
When you have determined which profiles consumers will evaluate, you must copy the dummy-coded profiles into an Excel or SPSS file. After that, you must remove one level for EACH ATTRIBUTE. Generally, the "worse" attribute or an "absent" level is deleted. For example, this is how our Excel file could look like:
When you have determined which profiles consumers will evaluate, you must copy the dummy-coded profiles into an Excel or SPSS file. After that, you must remove one level for EACH ATTRIBUTE. Generally, the "worse" attribute or an "absent" level is deleted. For example, this is how our Excel file could look like:
| Profile | RATING | Sugar | Chocolate | Flakes | Marshmallows |
|---|---|---|---|---|---|
| 1 | . | 1 | 0 | 1 | 0 |
| 2 | . | 1 | 0 | 0 | 0 |
| 3 | . | 0 | 1 | 1 | 1 |
Table 2: Excel spreadsheet removing one level per attribute
In Table 2, we removed the following levels:
The reason why we remove these will become clear in the next section. For more information on coding, download my notes on data coding from my Analytical Methods page. Finally, notice that there is a new column, called RATING, which is left blank. For each consumer you survey, you will create a spreadsheet like this, and copy their ratings for each profile there.
- Unflavored was removed from the flavor attribute;
- Nuggets was removed from the shape attribute;
- No Marshmallows was removed from the marshmallows attribute.
The reason why we remove these will become clear in the next section. For more information on coding, download my notes on data coding from my Analytical Methods page. Finally, notice that there is a new column, called RATING, which is left blank. For each consumer you survey, you will create a spreadsheet like this, and copy their ratings for each profile there.

|
Step 3:
|
Let's change gears, and assume that you're now interested in pricing a detergent. The main attributes and levels of detergents in your study are:
- Brand: Complete, Smile, and Wave.
- Scent: Fresh, Lemon, and Unscented.
- Softener: Yes/No.
- Size: 32oz., 48oz., 64oz.
- Price: $2.99, $3.99, $4.99.
How many potential product profiles could be produced in this context?
You could potentially come up with 3x3x2x3x3 = 162 product profiles. Clearly, no consumer would be willing to sit and rate all of those! Therefore, we created a smaller set of 23 profiles using the experimental design software SAS ADX:
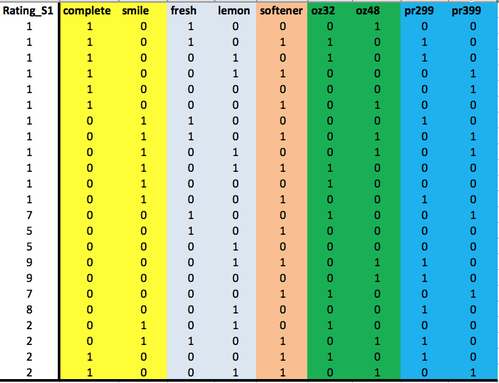
Figure 3: Our Excel/SPSS sheet for the detergent Conjoint Study. Notice how all ratings in this case are between 1 and 10. Can you describe each product profile by looking only at the table?
These profiles are easy to read. For example:
With this information at hand, all that remains is to come up with a technique that allows us to understand how each level of each attribute "contributes" to form this particular consumer's overall rating. For example, it could be that, among all attributes, only the Brand attribute matters, or perhaps only the Complete brand level matters. A useful technique to this end is known as Regression Analysis. Regression Analysis decomposes and separates the effects that many independent variables have on a single dependent variable. The analysis gives you the preference of this consumer for each attribute level. These are sometimes called "part-worths", or simply "preferences". Thus, you can think of the resulting preferences as levers or buttons that, when pressed, make consumers' more or less happy. To run a Regression Analysis, you can use either SPSS or Excel. Just make sure that:
1. Your rating variable is the dependent variable; and
2. All your dummies after removing one from each level are your independent variables;
You can run Regression Analysis in Excel by installing the Data Analysis toolpak (this works only for PC). In SPSS, you only need to go to Analyze -> Regression -> Linear.
The relevant results from running Regression Analysis on the data shown in Figure 3 is as follows:
- Profile 1 (first): Complete brand/Fresh scent/No softener/48 oz./$4.99
- Profile 23 (last): Complete brand/Lemon scent/With softener/48 oz./$3.99
With this information at hand, all that remains is to come up with a technique that allows us to understand how each level of each attribute "contributes" to form this particular consumer's overall rating. For example, it could be that, among all attributes, only the Brand attribute matters, or perhaps only the Complete brand level matters. A useful technique to this end is known as Regression Analysis. Regression Analysis decomposes and separates the effects that many independent variables have on a single dependent variable. The analysis gives you the preference of this consumer for each attribute level. These are sometimes called "part-worths", or simply "preferences". Thus, you can think of the resulting preferences as levers or buttons that, when pressed, make consumers' more or less happy. To run a Regression Analysis, you can use either SPSS or Excel. Just make sure that:
1. Your rating variable is the dependent variable; and
2. All your dummies after removing one from each level are your independent variables;
You can run Regression Analysis in Excel by installing the Data Analysis toolpak (this works only for PC). In SPSS, you only need to go to Analyze -> Regression -> Linear.
The relevant results from running Regression Analysis on the data shown in Figure 3 is as follows:
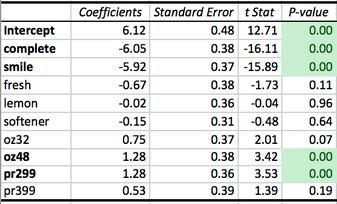
Figure 4: Regression Analysis results for Detergent study. Data is for a single consumer, in Figure 3.
What are the attribute LEVELS the consumer prefers more?
Let's think about what the numbers in the columns of Figure 4 mean:
- The first column just shows the names of each level. An additional level, called Intercept, is added. The Intercept represents consumers' "base" preference for all detergent products. Different levels of detergent attributes will make this base go up or down.
- The second column, Coefficients, displays the consumer's preference for each level.
- The last column, p-Value, holds a value between 0 and 1. Only levels whose p-value is smaller than or equal to 0.05 truly make a difference for the consumer.
Before continuing, it is important to understand how to interpret the preference estimates. For example, what does Complete=-6.05 mean? What does Price ($2.99)= 1.28 mean? For this, we need to return to our "dummy coding" scheme. Recall that we deleted one attribute level per attribute. This means that the resulting preference estimates reflect consumers' preference as compared to the deleted attribute!. That's it! The deleted levels serve as a baseline, or "benchmark", which is always 0. This is how the results look graphically:
Let's think about what the numbers in the columns of Figure 4 mean:
- The first column just shows the names of each level. An additional level, called Intercept, is added. The Intercept represents consumers' "base" preference for all detergent products. Different levels of detergent attributes will make this base go up or down.
- The second column, Coefficients, displays the consumer's preference for each level.
- The last column, p-Value, holds a value between 0 and 1. Only levels whose p-value is smaller than or equal to 0.05 truly make a difference for the consumer.
Before continuing, it is important to understand how to interpret the preference estimates. For example, what does Complete=-6.05 mean? What does Price ($2.99)= 1.28 mean? For this, we need to return to our "dummy coding" scheme. Recall that we deleted one attribute level per attribute. This means that the resulting preference estimates reflect consumers' preference as compared to the deleted attribute!. That's it! The deleted levels serve as a baseline, or "benchmark", which is always 0. This is how the results look graphically:
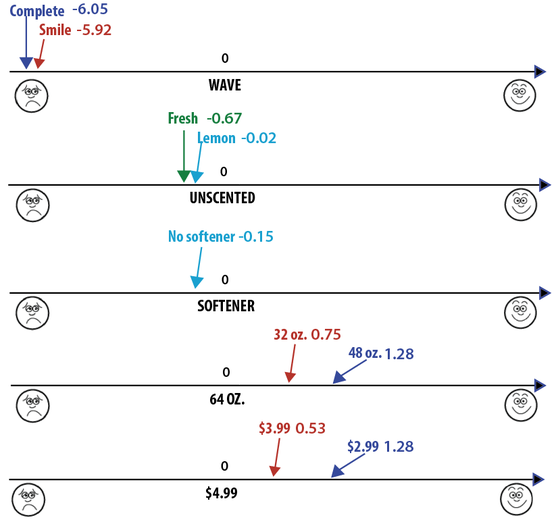
Figure 5: Interpretation of consumer preferences. For each level, interpret in relation to the benchmark you defined when you constructed the dummy set. Faces taken from the Wong-Baker FACES scale (http://www.wongbakerfaces.org).
Which is the worst brand? Which is the most preferred price level?
As you can see, preferences are interpreted with respect to the benchmark, valued at zero, regardless of which benchmark you defined! So, in this case, Wave is the most preferred brand. Because we set it as benchmark, brands worse than Wave have negative preferences, and brands better than Wave would have positive preferences. In addition, it is important to note that the distance between each level matters. For example, there is a huge difference between Wave and other brands in this consumer's mind. However, there is not so much difference between the Fresh, Lemon, and Unscented scents. These distances reflect how strong the preferences are.
What are the MOST IMPORTANT ATTRIBUTES overall?
This idea of distance has a powerful implication. As you noticed from Figure 5, the distances between the brand levels are very large, but others, such as the scent levels, are not. When consumers have stronger preferences for certain attributes, in general, the distances within its levels will be larger. With this idea in mind, we can calculate the importance of each attribute, regardless of its levels.
To compute the importance of each attribute, do the following for each one of them:
These importances represent how much the consumer prefers whole attributes, in big "chunks". So, once you have computed each importance, sum all of them. This would give you a number that represents, overall, how happy this consumer would be with the product. Finally, divide each importance by the sum. That would tell you the portion of consumers' happiness that each attribute, as a whole, conveys. Figure 6 explains this idea - warning, though: in Figure 6, the softener attribute was removed because of its small importance! This is why softener is not included.
What are the MOST IMPORTANT ATTRIBUTES overall?
This idea of distance has a powerful implication. As you noticed from Figure 5, the distances between the brand levels are very large, but others, such as the scent levels, are not. When consumers have stronger preferences for certain attributes, in general, the distances within its levels will be larger. With this idea in mind, we can calculate the importance of each attribute, regardless of its levels.
To compute the importance of each attribute, do the following for each one of them:
- Find out what is the least preferred attribute level for the attribute.
- Find out what is the most preferred attribute level for the attribute.
- Subtract the maximum minus the minimum.
These importances represent how much the consumer prefers whole attributes, in big "chunks". So, once you have computed each importance, sum all of them. This would give you a number that represents, overall, how happy this consumer would be with the product. Finally, divide each importance by the sum. That would tell you the portion of consumers' happiness that each attribute, as a whole, conveys. Figure 6 explains this idea - warning, though: in Figure 6, the softener attribute was removed because of its small importance! This is why softener is not included.

Figure 6: Calculating each attribute's importance - think of total importance as a tape that measures how happy the product makes the consumer. Each attribute occupies a different part of the tape. A larger part implies consumer cares more about that attribute!
With this information in hand, you now know that, for this consumer, brand is most important, followed by weight and price, and finally scent. Softener is negligible. Furthermore, using your p-Values, you can also determine that only the brands, as well as the 48 oz. weight and the $2.99 price point really make a difference for this particular consumer.

|
|
Up to now, you know:
What's missing? The best part - let's design consumers' ideal product! Recall that you now know this particular consumer's preferences for every attribute level. In addition, you know the value of the "Intercept" - a baseline preference that drops or rises, depending on which attribute levels a certain product has.
How do we know which is the ideal product? We simply need to design a bunch of them, and see which one makes this consumer happiest! For example, suppose we need to figure out which, among these four "candidate" products, would be most preferred:
- That products are composed of different attributes that, in turn, are composed of different levels;
- That we can discover consumers' preferences for those levels without specifically asking for them;
- That every time we discover consumer preferences for each attribute level, they are always relative to a particular level, which we deleted from our data;
- That not every level may make a difference for the consumer - specifically, those levels with a p-Value <.05.
- That we can calculate how important for each consumer each attribute is, regardless of its levels, by using level preferences.
What's missing? The best part - let's design consumers' ideal product! Recall that you now know this particular consumer's preferences for every attribute level. In addition, you know the value of the "Intercept" - a baseline preference that drops or rises, depending on which attribute levels a certain product has.
How do we know which is the ideal product? We simply need to design a bunch of them, and see which one makes this consumer happiest! For example, suppose we need to figure out which, among these four "candidate" products, would be most preferred:
| Candidate | Brand | Scent | Softener | Size | Price |
|---|---|---|---|---|---|
| 1 | Complete | Lemon | With softener | 48oz. | $4.99 |
| 2 | Wave | Unscented | No softener | 64oz. | $2.99 |
| 3 | Wave | Unscented | Softener | 32oz. | $4.99 |
| 4 | Smile | Fresh | No softener | 48oz. | $3.99 |
Table 3: Five candidates for this consumer’s love: Which will come out on top?
How would a myopic marketer, who **did not** conduct Conjoint Analysis, would go about finding consumers' ideal product? How will **you** do it using preference information?
Figuring out which product among these four is the consumers' ideal product is very simple. You know consumers' baseline preference (Intercept) and how consumers' baseline preference changes with each attribute level. So, it's as simple as summing! For example, let's figure out how preferred candidate 1 would be:
1. Start with the Intercept: A base preference of 6.12
2. Next, add the brand preference (Complete): 6.12 + (-6.05) = 0.07.
3. Next, add the scent preference(Lemon): 6.12 + (-6.05) + (-0.02) = 0.05
4. Next, add the softener preference (With softener): 6.12 + (-6.05) + (-0.02) + (-0.15) = -0.1
5. Next, add the size preference (48oz.) = 6.12 + (-6.05) + (-0.02) +(-0.15) + 1.28 = 1.18
6. Finally, add the price preference ($4.99) = 6.12 + (-6.05) + (-0.02) + (-0.15) + 1.28 + 0 = 1.18
1. Start with the Intercept: A base preference of 6.12
2. Next, add the brand preference (Complete): 6.12 + (-6.05) = 0.07.
3. Next, add the scent preference(Lemon): 6.12 + (-6.05) + (-0.02) = 0.05
4. Next, add the softener preference (With softener): 6.12 + (-6.05) + (-0.02) + (-0.15) = -0.1
5. Next, add the size preference (48oz.) = 6.12 + (-6.05) + (-0.02) +(-0.15) + 1.28 = 1.18
6. Finally, add the price preference ($4.99) = 6.12 + (-6.05) + (-0.02) + (-0.15) + 1.28 + 0 = 1.18
Be very careful!!: when we added the price preference $4.99 was defined as our "benchmark" level for the Price attribute. Therefore, its preference is set at 0, as we saw in Figure 5 when we interpreted preferences.
As you can see, this is a very straightforward calculation. The end result? This consumer's preference for candidate product 1 is 1.18. Of course, without knowing how preferred the rest of the products are, this number makes no sense. So, let us calculate the preference for all our candidates and figure out which one is ideal:
| Candidate | Brand | Scent | Softener | Size | Price | Preference |
|---|---|---|---|---|---|---|
| 1 | Complete | Lemon | With softener | 48oz. | $4.99 | 6.12 + (–6.05) + (–0.02) + (–0.15) + 1.28 + 0 = 1.18 |
| 2 | Wave | Unscented | No softener | 64oz. | $2.99 | 6.12+0+0+0+0+1.28=7.4 |
| 3 | Wave | Unscented | Softener | 32oz. | $4.99 | 6.12+0+0+(–0.15)+0.75+0=6.72 |
| 4 | Smile | Fresh | No softener | 48oz. | $3.99 | 6.12+(–5.92)+(–0.67)+0+1.28+0.53=1.34 |
Table 4: With preferences in hand, product candidate 2 wins!
If you had to choose from the above four designs to satisfy this consumer, the obvious choice is to design and launch product candidate 2 as your new product. As you can see, this is much, much better than trying to blindly design a new product or deciding based on a couple of focus groups.
More striking is how much we gain from learning about ideal product design. Although we used only 23 profiles to obtain preferences for attribute levels, we could potentially determine how preferred each and every single product among the 162 potential designs is for this one consumer following the procedure shown in Table 4. After doing this, we find the following distribution of preferences:
More striking is how much we gain from learning about ideal product design. Although we used only 23 profiles to obtain preferences for attribute levels, we could potentially determine how preferred each and every single product among the 162 potential designs is for this one consumer following the procedure shown in Table 4. After doing this, we find the following distribution of preferences:
| Preference | # of designs | % of designs | Avg. preference |
|---|---|---|---|
| Negative | 10 | 6.17% | –0.3 |
| Low (0–2.76) | 98 | 60.49% | 1.25 |
| Medium (5.3–7.93) | 45 | 27.78% | 6.86 |
| High (>7.93) | 9 | 6.17% | 8.29 |
Table 5: For this consumer, a couple products are terrible; most are mediocre; less than 10 guarantee success.
As you can see, among the more than 100 potential product designs, less than 10% of them would be most preferred by this person. This is why using Conjoint Analysis to find consumers' ideal product is so helpful.
What do you think is the best design?
As it turns out the best design is a Wave detergent, unscented, with no softener, weighing 48 oz., at a price of $2.99. This product has a preference score of 8.68.
What if I want to learn about preferences for MORE than one consumer?
Naturally, examining preferences for only one consumer is not the best way to design a product. However, so far, we have only addressed a single consumer. To calculate preferences that may be more representative of the market, you should do the following:
What if I want to learn about preferences for MORE than one consumer?
Naturally, examining preferences for only one consumer is not the best way to design a product. However, so far, we have only addressed a single consumer. To calculate preferences that may be more representative of the market, you should do the following:
- Apply the Conjoint survey to a group of consumers, say, 50;
- Conduct Regression Analysis on each of the 50 consumers’ profile ratings separately. This will give you 50 tables as the one shown in Figure 4 (you can ignore the Intercept).
- Average those coefficients. For example, we recorded detergent ratings for 4 additional consumers. We separately analyzed each of the 5 ratings, obtaining the resulting table:
| Coefficient | Subject 1 | Subject 2 | Subject 3 | Subject 4 | Subject 5 | Average |
|---|---|---|---|---|---|---|
| Complete | –6.05 | –0.11 | –0.26 | 0.25 | –0.28 | -1.29 |
| Smile | –5.92 | 0.81 | –0.08 | 0.52 | 0.64 | –0.81 |
| Fresh | –0.67 | –0.78 | 1.00 | –0.52 | –1.39 | –0.47 |
| Lemon | –0.02 | 0.01 | 0.67 | 0.08 | –4.29 | –0.71 |
| Softener | –0.15 | 0.08 | –1.98 | –0.29 | –0.11 | –0.49 |
| 32oz. | 0.75 | –5.91 | –1.08 | –3.30 | –0.98 | –2.10 |
| 48oz. | 1.28 | –1.38 | –0.26 | –1.93 | –1.17 | –0.69 |
| $2.99 | 1.28 | 3.79 | 2.07 | 4.66 | 2.77 | 2.91 |
| $3.99 | 0.53 | 2.47 | 3.48 | 3.88 | 2.03 | 2.48 |
Table 6: Average preferences for every attribute level on a 5-subject sample.
Note that the “Subject 1” column reflects the preferences we found earlier in Figure 4. Also, recall that, for our first consumer, brand was the most important (specifically, 65%, as shown in Figure 6). Does this hold when we consider average preferences across several consumers? Judge for yourself:
| Attribute | Maximum | Minimum | Importance for 5 subjects |
|---|---|---|---|
| Brand | 0 | –1.29 | 1.29 (17.17%) |
| Scent | 0 | –0.71 | –0.71 (9.46%) |
| Softener | 0 | –0.49 | 0.49 (6.52%) |
| Size | 0 | –2.10 | 2.10 (28.02%) |
| Price | 2.91 | 0 | 2.91 (38.83%) |
Table 7: Average importance for detergent attributes on a 5-subject sample.
Do the 5-subject sample importances look like the ones calculated for our first subject?
As can be seen, a reasonably sized sample would be ideal for investigating consumers’ ideal products. Make sure you conduct the Conjoint Analysis study with at least 30 subjects.
How do we predict market share for the product we choose to launch?
To predict market shares, you must first determine the following. Among the product designs you can evaluate based on consumer preferences, which are most likely to be on the shelves alongside your newly launched product? This constitutes the set of products consumers will compare to decide what to buy - this is known as consumers’ consideration set.
Once you have determined consumers’ consideration set, you need to conduct the following analysis for each consumer in the sample:
Once you determine what consumers’ would have most likely chosen, you can simply compute the percentage of predicted choices for each product. For example, if you survey 20 individuals, whose consideration set consists of 6 products, and 7 individuals choose Design 1, then Design 1 would obtain a market share of 7/20 = 35%. That’s it! You can practice using our class dataset here.
How do we predict market share for the product we choose to launch?
To predict market shares, you must first determine the following. Among the product designs you can evaluate based on consumer preferences, which are most likely to be on the shelves alongside your newly launched product? This constitutes the set of products consumers will compare to decide what to buy - this is known as consumers’ consideration set.
Once you have determined consumers’ consideration set, you need to conduct the following analysis for each consumer in the sample:
- Obtain preference estimates.
- Next, calculate how preferred each product in the consideration set would be, according to those preferences.
- The product with the maximum preference among all products in the consideration set is the one you would expect the consumer to choose. This is known as the maximum utility rule: whatever is predicted to be most preferred is assumed would be chosen by that subject. Other rules, such as the logit rule, exist.
Once you determine what consumers’ would have most likely chosen, you can simply compute the percentage of predicted choices for each product. For example, if you survey 20 individuals, whose consideration set consists of 6 products, and 7 individuals choose Design 1, then Design 1 would obtain a market share of 7/20 = 35%. That’s it! You can practice using our class dataset here.

|
|
Consumer Reports. 2014. The downside of too many product choices on store shelves. Consumer Reports, January 2014. Accessed February 18, 2014 (Source).
Luo, Lan, Brian T. Ratchford, P.K. Kannan. 2009. Incorporating Subjective Characteristics in Product Design and Evaluations. Journal of Marketing Research 45(2), pp. 182–194.
Wind, Jerry, Paul E. Green, Douglas Shifflet and Marsha Scarbrough. Courtyard by Marriott: Designing a Hotel Facility With Consumer-Based Marketing Models. Interfaces 19(1), pp. 25–47.
Luo, Lan, Brian T. Ratchford, P.K. Kannan. 2009. Incorporating Subjective Characteristics in Product Design and Evaluations. Journal of Marketing Research 45(2), pp. 182–194.
Wind, Jerry, Paul E. Green, Douglas Shifflet and Marsha Scarbrough. Courtyard by Marriott: Designing a Hotel Facility With Consumer-Based Marketing Models. Interfaces 19(1), pp. 25–47.